


Automated quality checks on your HANA models. It is possible!
Introduction
Making sure that every developer sticks to the programming standards and validating code quality is always challenging. Especially for HANA models, as the calculation views are only visible in a graphical way. Checking all the views manually is almost impossible due to the sheer quantity. Wouldn’t it be nice to get an automatic overview of all HANA models and see if they are built according to the modeling guidelines? We have a solution for you!
In this blog I focus on a way to extract information from the graphical views by taking the ‘raw model data’ as a basis for the analysis. This raw data is an XML file that allows for automated quality checks of your HANA models. This requires technical knowledge … I can assure you that it is worth reading if you like to get your hands dirty 😉 !
Use cases
Before diving into the technical details, first some more information on the actual usage and benefits of this approach.
As a start all HANA Model information in the XML document can be extracted. This information can provide HANA view developers with an automatically generated overview of validations. In this way, already before the created HANA model is being reviewed by another developer, the original developer of the HANA view can already validate his/her work and implement enhancements.
Next to the automated quality checks mentioned above there is more! Another use case can be the migration of HANA models, for example, when converting HANA models from XSC towards XSA. Migration of these models cannot be done when Column Engine is used in the models. In this blog we hand you the tools to be able to find out where Column Engine is used without having to click through all the models manually to perform this check but it can be done automatically, significantly speeding up the migration process.
Now let’s dive into the details!
Technical deep dive
Each HANA model has a XML document in which the HANA model is described. This XML document describes the information in a structured way.
XML structure
In short, XML stands for “eXtensible Markup Language” and is a standard for describing data objects. For our purpose, it is important to know that a XML document is build based on the following structure:

An part of a XML document of a HANA model is shown below, where the different objects are being highlighted:

XMLEXTRACTVALUE function
To extract information from the XML document, we use the XMLEXTRACTVALUE function. In the SAP HANA SQL Reference guide, this function is briefly discussed but it would make sense to clarify this function with examples.
The XML extract value function consists of 3 syntax elements that need to be defined:
XMLEXTRACTVALUE(<XML_document>, <XPath_query> [,<NamespaceDeclarations>])
- XML document
- When zooming in on each record, the XMLEXTRACTVALUE function is able to look for specific properties within the XML document.
- XPath query
- The second – and most important – part within that function is the “<XPath_query>”. Xpath is a query language that can be used to extract information from the XML file (more information can be found here).
- Namespace Declaration
- The last part is the namespace declaration. These namespaces are static and can be found in the first line of the XML document of the file you want to extract data from. The value of the attribute “xmlns:xsi” should be used for the namespace.
Implementation of XMLEXTRACTVALUE
As we have seen in the previous paragraph, the XMLEXTRACTVALUE function needs 3 elements for input. Let’s zoom in on each of the elements specifically in the context of HANA models:
- XML document
Each HANA model is saved as a XML file, the content of this XML file is stored within the SAP table “_SYS_REPO”.”ACTIVE_OBJECT”, field “CDATA”.
A query that can be used to get the XML content for HANA models is as follows:
SELECT
CDATA
FROM
_SYS_REPO.ACTIVE_OBJECT
WHERE
OBJECT_SUFFIX = ‘calculationview’
Example output when running the query above (where we see that CDATA field contains the whole XML content):
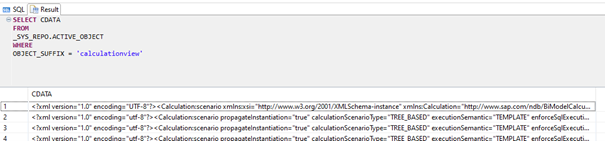
- Xpath query
Each attribute within a XML document can be identified using the Xpath query.
In general, the Xpath query can be constructed using the element and the attribute which is being considered:
![]()
When we are looking to retrieve information about the technical name of the HANA model, we see in the XML document of the HANA model that the element “Calculation:scenario” has an attribute called “id” which contains the technical name of the HANA model:

This therefore can used to construct the Xpath query for this example based on the template “<element>/@attribute”:
![]()
- Namespace declaration
The namespace declaration is a constant for each object (e.g. HANA model). This value can be found in the first line of the XML document of the HANA model linked to the attribute “xmlns:xsi”. Specifically to extract information from HANA models, this constant is equal to:
'xmlns:xsi=http://www.w3.org/2001/XMLSchema-instance xmlns:Calculation=http://www.sap.com/ndb/BiModelCalculation.ecore'
Building procedures with XMLEXTRACTVALUE function
A complete example of how the XMLEXTRACTVALUE function can be implemented in a procedure in order to extract information from a HANA model:
--Define namespace constant for HANA models DECLARE LV_XMLNS NVARCHAR(500) := 'xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:Calculation="http://www.sap.com/ndb/BiModelCalculation.ecore"'; --Populate content of XML file for HANA model LT_XML =
SELECT CDATA
FROM _SYS_REPO.ACTIVE_OBJECT
WHERE OBJECT_SUFFIX = ‘calculationview”;
SELECT
XMLEXTRACTVALUE(CDATA, ‘/Calculation:scenario/@id ‘, :LV_XMLNS )
FROM
:LT_XML;
This SQL statement will extract the attribute “id” that is referring to the technical name of the calculation views from the local table “LT_XML”. The local table LT_XML is already being populated with the XML document of the HANA model that we would like to extract data from.
When building procedures using the XMLEXTRACTVALUE function, some attributes do not exist when the attribute is optional within the object of the XML document. Important to note is that when an attribute is optional and no value is assigned within the calculation view, searching for that attribute will not give any result. For example when calculation view A does not have a comment on the Semantics node but calculation view B does have a comment on the Semantics node, the Xpath query to get the comment is exactly the same but the XMLEXTRACTVALUE function will return nothing when performed for calculation view A.
To ensure that the procedure will not end in an error, a continue handler can be inserted into the procedure:
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION BEGIN END;
More inspiration
Now that you understand the technical details, below are some more use cases for your inspiration:
- Are comments added:
- on view level in the Semantics node; to explain the goal of the view
- on calculated columns; to explain the reason and logic for the calculation
- on aggregation/projection nodes; to explain filters/logic being applied
- Overview of the objects like other HANA views and/or functions that are being consumed in the view; to get a good understanding of dependencies
- Are there special settings being applied within the HANA model. One of those settings is the “KeepFlag” property for exception aggregation. This would be important to know and is not directly visible when looking at the view.
In the table below you will find a couple of examples related to HANA models with the SQL statement that could be used in a procedure:
| Type of data to be extracted |
SQL Statement | Remark |
| The cardinality of a join node |
SELECT XMLEXTRACTVALUE(CDATA, ‘/Calculation:scenario/calculationViews/calc ulationView[‘||:lv_join_node_number||’]/@car dinality’, :LV_XMLNS ) FROM :LT_XML; |
Since a HANA model can contain multiple joins, we will implement loop logic to extract cardinality based on variable “lv_join_node_number” |
| The filter applied on aggregation/ projection nodes |
SELECT XMLEXTRACTVALUE(CDATA, ‘/Calculation:scenario/calc ulationViews/calculationView[‘||:lv_node_number||’]/filter’, :LV_XMLNS ) FROM :LT_XML; |
Since a HANA model can contain multiple aggregation/projection nodes, we will implement loop logic to extract cardinality based on variable “lv_node_number” |
| The option to apply exception aggregation | SELECT XMLEXTRACTVALUE(CDATA, ‘/Calculation:scenario/logicalModel/attribute s/attribute[‘||:lv_characteristic_number||’]/@ keepFlag’, :LV_XMLNS ) FROM :LT_XML; |
By enabling the KeepFlag attribute, exception aggregation will be applied based on that characteristic. Here also a loop is applied such that for each characteristic (variable “lv_characteristic_number”) this option can be checked |
| The exchange rate type being applied for currency conversion | SELECT XMLEXTRACTVALUE(CDATA, ‘/Calculation:scenario/logicalModel/calculat edMeasures/measure[‘||:lv_currency_conver sion_number||’]/currencyConversion/exchan geRateType’, :LV_XMLNS ) FROM :LT_XML; |
Since a HANA model can contain multiple currency conversions, we will implement loop logic to extract exchange rate type based on variable “lv_currency_conversion_number” |
| The ability to see whether Column Engine is applied on node level for example on Projection nodes | SELECT XMLEXTRACTVALUE(CDATA, ‘/Calculation:scenario/calculationViews/calc ulationView[‘||:lv_node_number||’]/@filterExp ressionLanguage’, :LV_XMLNS ) FROM :LT_XML; |
Since a HANA model contains multiple nodes, we will implement loop logic to extract the engine used based on variable “lv_node_number”
For migration to XSA, all logic defined with the Column Engine should be adjusted. This statement will give an overview to see which engine is used (e.g. ‘SQL’ or ‘COLUMN_ENGINE’) |
Conclusion
The XMLEXTRACTVALUE function is a very powerful tool to use in the context of XML documents. However, it does require a good understanding of XML structure and the XPath in order to extract data from complex objects such as HANA models.
When you or your team is interested and want more information about this, please reach out to us and we will be more than happy to help! We as Interdobs have extensive experience with this function.