

HANA performance verbetering door geautomatiseerd persisteren
Een goed gemodelleerd HANA model kan in de meeste gevallen volledig virtueel worden opgezet. De data wordt één keer persistent opgeslagen en alle transformaties en rapport specifieke logica wordt in virtuele modellen aangeboden. Er zijn uitzonderingen waarbij het toch handig is om data nogmaals persistent op te slaan om aan specifieke (rapportage) eisen te voldoen. Bijvoorbeeld bij performance eisen voor rapportages waar het reguliere model niet aan kan voldoen of bij het maken van snapshots van data. Die wens om data toch te persisteren ontstaat meestal pas halverwege het project of pas na implementatie. Deze blog gaat over het automatiseren van dit proces en hoe er op een eenvoudige manier, geautomatiseerd, een grote performance winst gehaald kan worden.
Views met slechte performance herkennen
Het herkennen van views die in aanmerking komen om te persisteren zullen we niet in veel detail behandelen. Het kan zijn dat een gebruiker zich meldt met een rapportage performance behoefte, dat een SQL statement opvalt bij het monitoren van performance of memory gebruik of dat er bij het ontwerpen al in een unit test blijkt dat de minimale performance niet gehaald kan worden. We gaan er voor deze blog vanuit dat andere performance verbeterende acties al zijn toegepast en dat het persisteren van de data de beste keuze is.
Persistente tabellen geautomatiseerd genereren
De eerste stap is het maken van een tabel die de persistente data van een view kan opslaan. Dit willen we automatiseren, want zeker als een view een flink aantal velden heeft kan dit veel werk opleveren. Hiervoor schrijven we een procedure. Deze heeft als input een bron view, een gewenst schema en tabelnaam en een actie type (create, update of delete). De output is een code om aan te geven of de actie geslaagd is of dat er fouten waren.

In “_SYS_BI”.”BIMC_PROPERTIES” staat de definitie van alle views. Op basis van de view die als input is meegegeven kunnen we daar alle velden met datatype uit halen. In “_SYS_BI”.”BIMC_PROPERTIES” staan alle tabellen. Dit is nodig voor als we een update willen uitvoeren, bijvoorbeeld als er velden in de view zijn bijgekomen die nu ook in de tabel moeten komen.
Op basis van deze input kunnen we een SQL statement schrijven om een tabel te maken, te updaten of te verwijderen. Dit is afhankelijk van het actie type bij het aanroepen van de procedure. Als voorbeeld nemen we een create statement. Simpel gezegd ziet die er als volgt uit:
CREATE TABLE “SCHEMA”.”TABELNAAM” (VELD1 DATATYPE1, VELD2 DATATYPE2, …);
Een cursor op de BIMC_PROPERTIES geeft een lijst van alle view velden.
 Het opbouwen van het SQL statement kan dan als volgt. Onderstaande geeft een nieuwe tabel met exact dezelfde veldnamen en datatypes als de view.
Het opbouwen van het SQL statement kan dan als volgt. Onderstaande geeft een nieuwe tabel met exact dezelfde veldnamen en datatypes als de view.
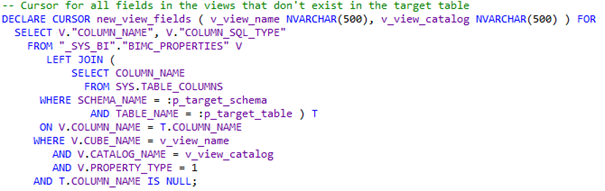
 Bij een update statement kijken we alleen naar velden die wel in de view zitten, maar nog niet in de tabel. Een cursor ziet er dan als volgt uit. We joinen BIMC_PROPERTIES met TABLE_COLUMNS en in de where statement nemen we alle velden mee die NULL zijn, dus niet voorkomen, in TABLE_COLUMNS.
Bij een update statement kijken we alleen naar velden die wel in de view zitten, maar nog niet in de tabel. Een cursor ziet er dan als volgt uit. We joinen BIMC_PROPERTIES met TABLE_COLUMNS en in de where statement nemen we alle velden mee die NULL zijn, dus niet voorkomen, in TABLE_COLUMNS.
 Het update SQL statement is ook relatief eenvoudig, vergelijkbaar met het create statement. Bij het verwijderen van de tabel kan een simpele drop table worden uitgevoerd.
Het update SQL statement is ook relatief eenvoudig, vergelijkbaar met het create statement. Bij het verwijderen van de tabel kan een simpele drop table worden uitgevoerd.
Als het benodigde SQL statement is opgebouwd kan dit direct worden uitgevoerd met een EXECUTE IMMEDIATE statement. De tabel is dan gemaakt, aangepast of verwijderd. We slaan nu een boel controle en logging stappen over, zie hiervoor ook de overige aandachtspunten verderop in dit blog.
Persistente tabellen geautomatiseerd vullen
Het vullen van de tabel willen we ook via een procedure kunnen doen. De view en tabel zijn weer input, nu aangevuld met een update type (update of delete van data), input parameters van de view en selecties voor de view/tabel. De output is opnieuw een code om aan te geven of de actie geslaagd is of dat er fouten waren.
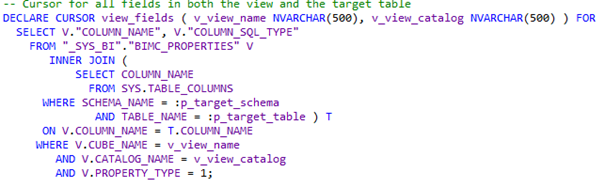
 Vergelijkbaar met het maken van de tabel, hebben we een SQL statement nodig voor het updaten van de data in de tabel. Dit kan een insert into, delete from of truncate statement worden, of een combinatie. We gaan uit van een update statement inclusief een selectie, waarbij we eerst data van die selectie verwijderen uit de tabel en daarna updaten vanuit de view met dezelfde selectie.
Vergelijkbaar met het maken van de tabel, hebben we een SQL statement nodig voor het updaten van de data in de tabel. Dit kan een insert into, delete from of truncate statement worden, of een combinatie. We gaan uit van een update statement inclusief een selectie, waarbij we eerst data van die selectie verwijderen uit de tabel en daarna updaten vanuit de view met dezelfde selectie.
De eerste stap is bepalen welke velden we moeten bijwerken. Het kan zijn dat de tabel slechts een deel van de view velden persistent opslaat of dat door historische aanpassingen er velden in de tabel zitten die nu niet meer in de view zitten. We maken daarom een cursor voor alle velden die zowel in de tabel als in de view zitten.
 De SQL statement voor het verwijderen van data uit de tabel en de SQL voor het vullen van de tabel vanuit de view bouwen we los van elkaar op. Op deze manier kunnen ze ook tegelijk worden uitgevoerd en loop je geen risico dat data (tijdelijk) weg is uit de tabel. We beginnen met het verwijderen van data. Dit kan een truncate zijn als er geen selectie is meegegeven, anders moeten we een delete from uitvoeren.
De SQL statement voor het verwijderen van data uit de tabel en de SQL voor het vullen van de tabel vanuit de view bouwen we los van elkaar op. Op deze manier kunnen ze ook tegelijk worden uitgevoerd en loop je geen risico dat data (tijdelijk) weg is uit de tabel. We beginnen met het verwijderen van data. Dit kan een truncate zijn als er geen selectie is meegegeven, anders moeten we een delete from uitvoeren.
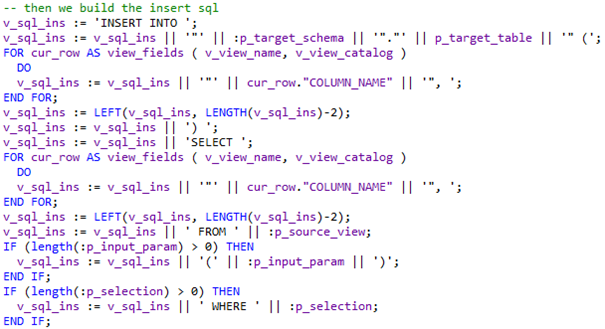
 Vervolgens komt het insert into statement. Hierbij gaan we uit van een simpel basis statement:
Vervolgens komt het insert into statement. Hierbij gaan we uit van een simpel basis statement:
INSERT INTO “SCHEMA”.”TABELNAAM” (VELD1, VELD2, …) SELECT VELD1, VELD2, … FROM “VIEW” WHERE SELECTIE_VELD = SELECTIE_WAARDE;
Afhankelijk van of er parameters of selectievelden worden meegegeven moet het SQL statement met parameter input of een where statement worden opgebouwd, hierdoor wordt de code iets complexer.
Als beide SQL statements zijn opgebouwd kunnen ze worden uitgevoerd. Ook hier slaan we controles en logging even over voor het gemak van de blog.
Mogelijkheden voor delta verwerken
Om de tabel actueel te houden moet er nog een update ingepland worden. Afhankelijk van de bron kan dit ingepland worden vanuit HANA of vanuit BW, bijvoorbeeld op een vaste tijd of na het laden van de bronnen die gebruikt worden in de HANA view. Er zijn hier ook weer verschillende opties om een deel van de data of de volledige tabel bij te werken.
Een volledige update kan als de data niet vaak wijzigt en/of de view snel kan worden uitgevoerd. In dat geval kan de update procedure met een vast commando worden aangeroepen zonder selectie. Er zal dan altijd een truncate en een insert into worden uitgevoerd.
Een delta op variabele (tijd) selectie kan ook worden gebruikt. Dit kan als de view bijvoorbeeld een creatiedatum heeft of als het financiële data betreft die na een periode sluiting niet meer wijzigt. We gebruiken dan een tweede procedure om de update procedure aan te roepen met een (tijd) selectie in de aanroep. Zo kan je alle data met een creatiedatum in de afgelopen x dagen updaten of het volledige huidige boekjaar. Omdat de selectieve verwijdering en update met dezelfde selectie worden uitgevoerd gaat er geen data verloren.
Mocht het bovenstaande niet kunnen dan is een ander, complexer, scenario mogelijk. Op basis van changelogs in één of meerder ADSO’s wordt dan bepaald welke selectie bijgewerkt moet worden. Dit vereist wel een goede kennis van het onderliggende datamodel. Omdat dit zeer specifieke scenario’s zijn zal ik hier geen voorbeeld van geven.
Overige aandachtspunten
Er is een aantal aandachtspunten voor het implementeren van deze oplossing die we voor de blog achterwege hebben gelaten. Hieronder wil ik deze toch nog even benoemen:
Afhankelijke objecten
In veel gevallen zal een view die persistent wordt gemaakt in andere views gebruikt worden. Het is mogelijk om deze automatisch te vervangen door in de afhankelijke views de datasource te wijzigen van de originele view naar de nieuwe persistente tabel. Ook dit doen we in een procedure waarbij we eerst de huidige versie van de view uit “_SYS_REPO”.”ACTIVE_OBJECT” wegschrijven als versie in “_SYS_REPO”.”OBJECT_HISTORY” en vervolgens passen we de versie in “_SYS_REPO”.”ACTIVE_OBJECT” aan. Zo behouden we altijd de mogelijkheid om terug te gaan naar de originele versie van de afhankelijke view. Uiteraard kan dit ook een handmatige actie zijn.
Logging
Zowel bij het maken van tabellen als bij het vullen loggen we in aparte tabellen voor iedere actie wanneer en door wie deze is uitgevoerd. Zeker als we afhankelijke views weer willen laten verwijzen naar de originele view of als we een overzicht willen maken van wanneer persistente tabellen worden bijgewerkt is dit essentieel.
Ingebouwde controles en errorcodes
Bij het maken en vullen van tabellen controleren we of de view bestaat, of de tabellen bestaan, of de SQL statements succesvol zijn uitgevoerd, etc. Als je dit niet zou doen zou de procedure als black box werken en is het niet zichtbaar of data actueel is en of er fouten optreden in het proces.
Vragen of hulp nodig?