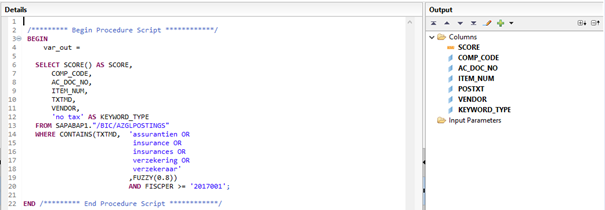
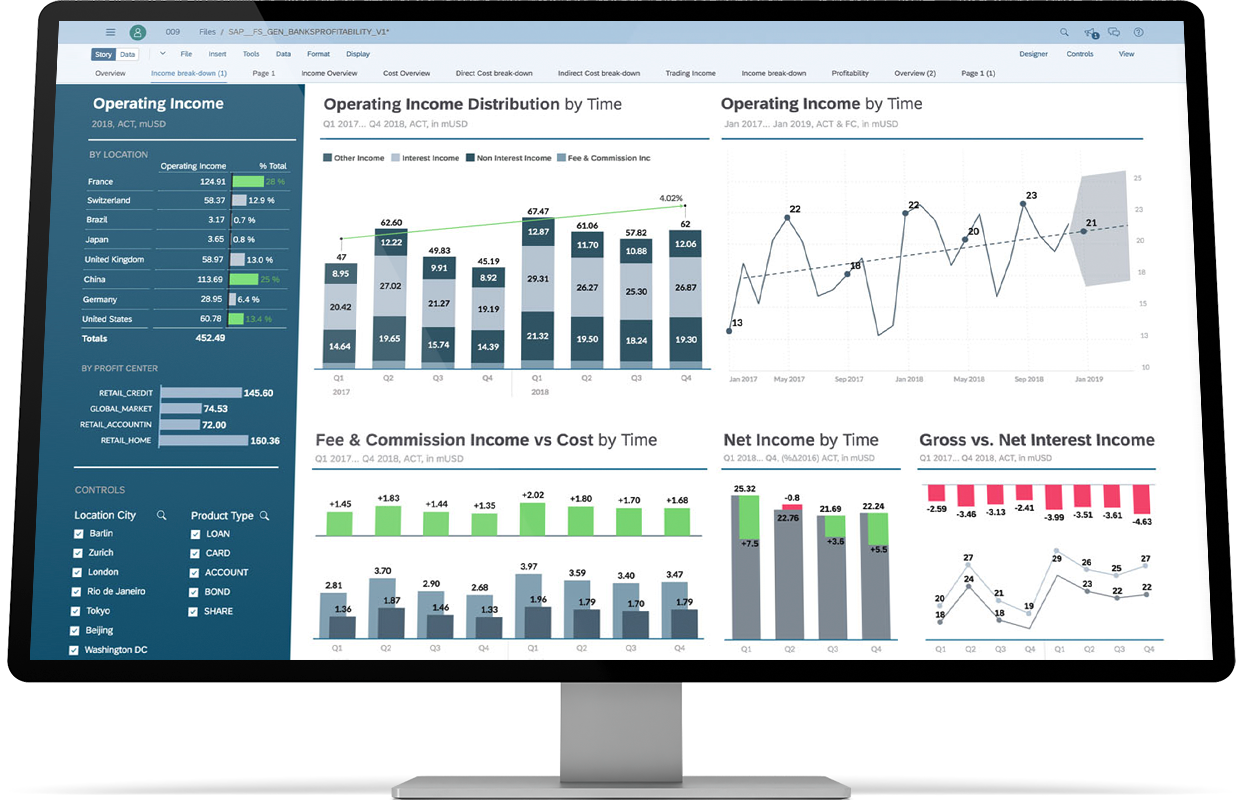
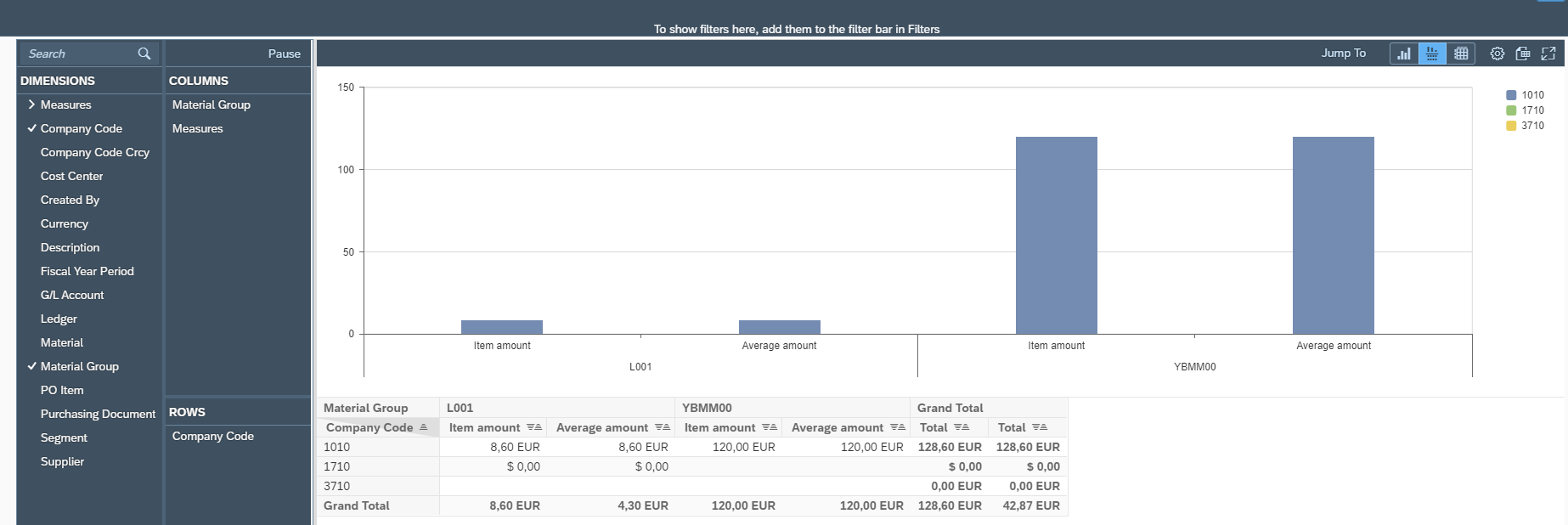
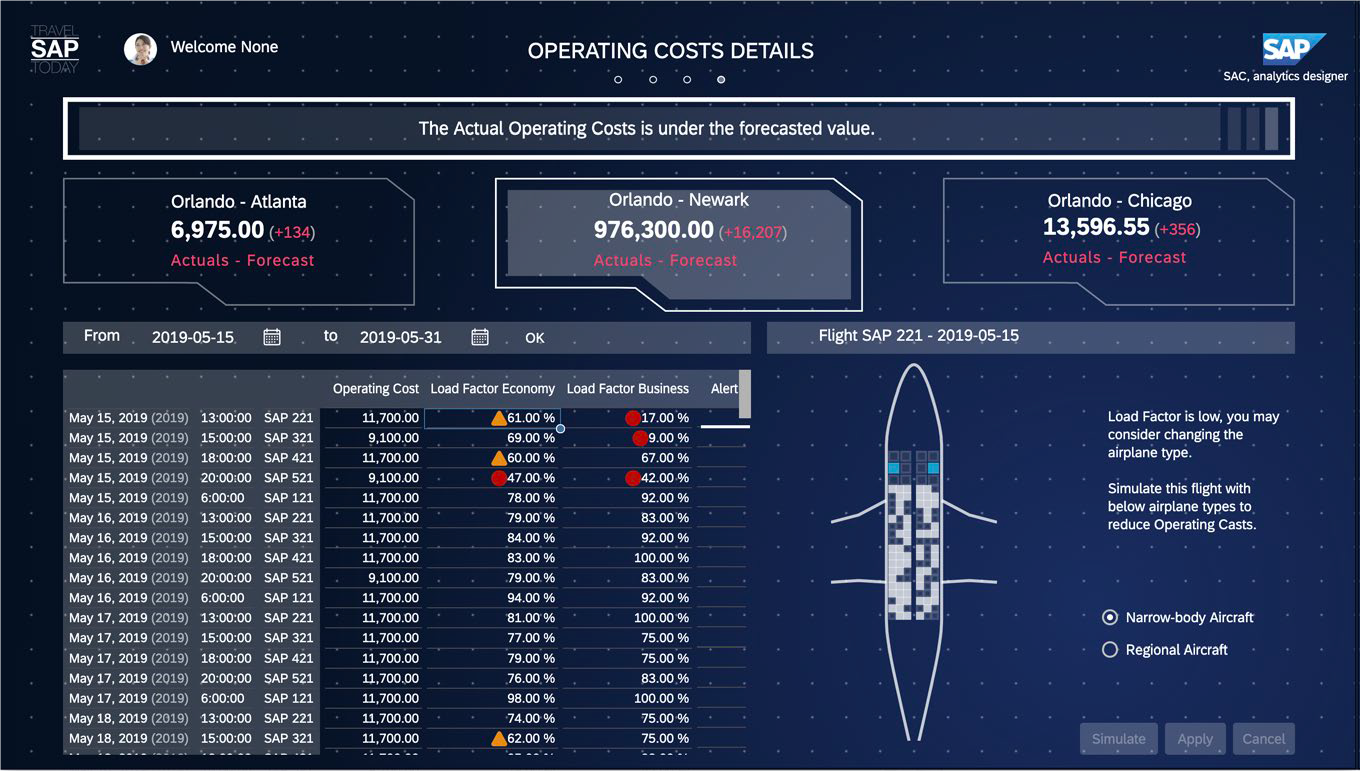
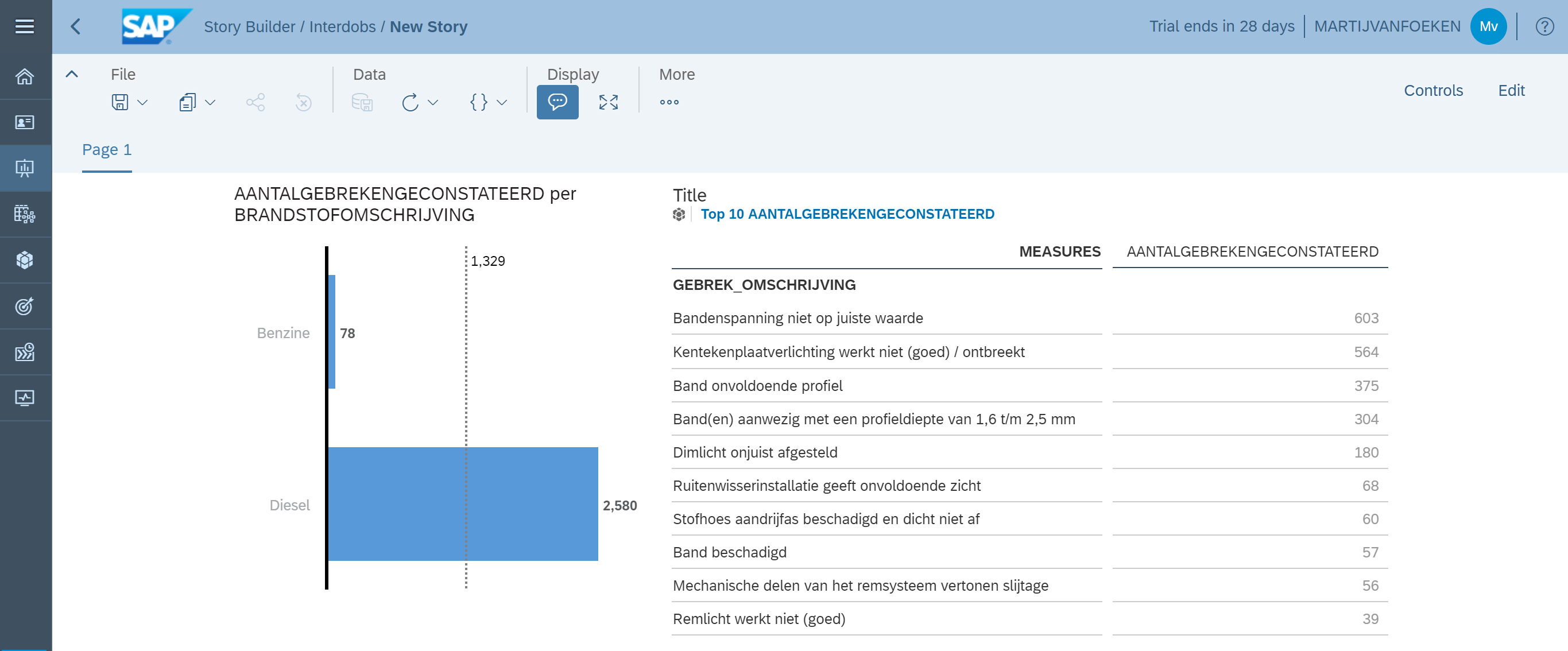
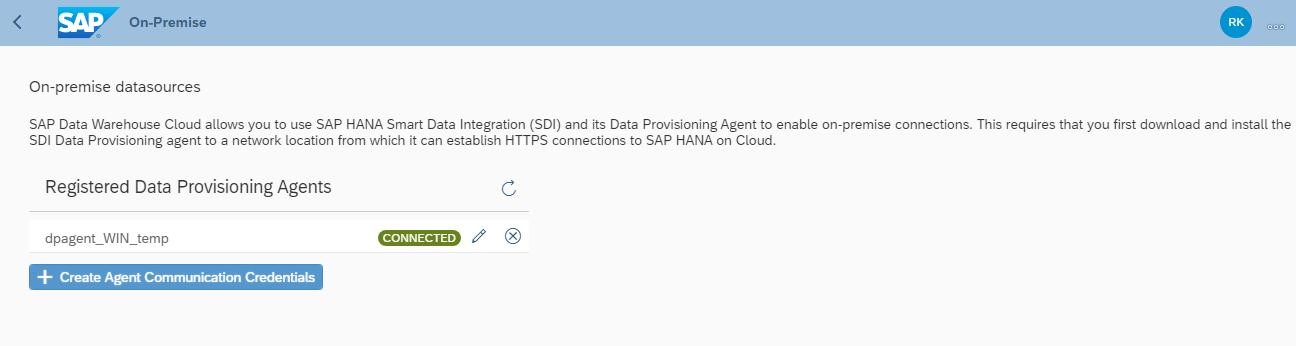
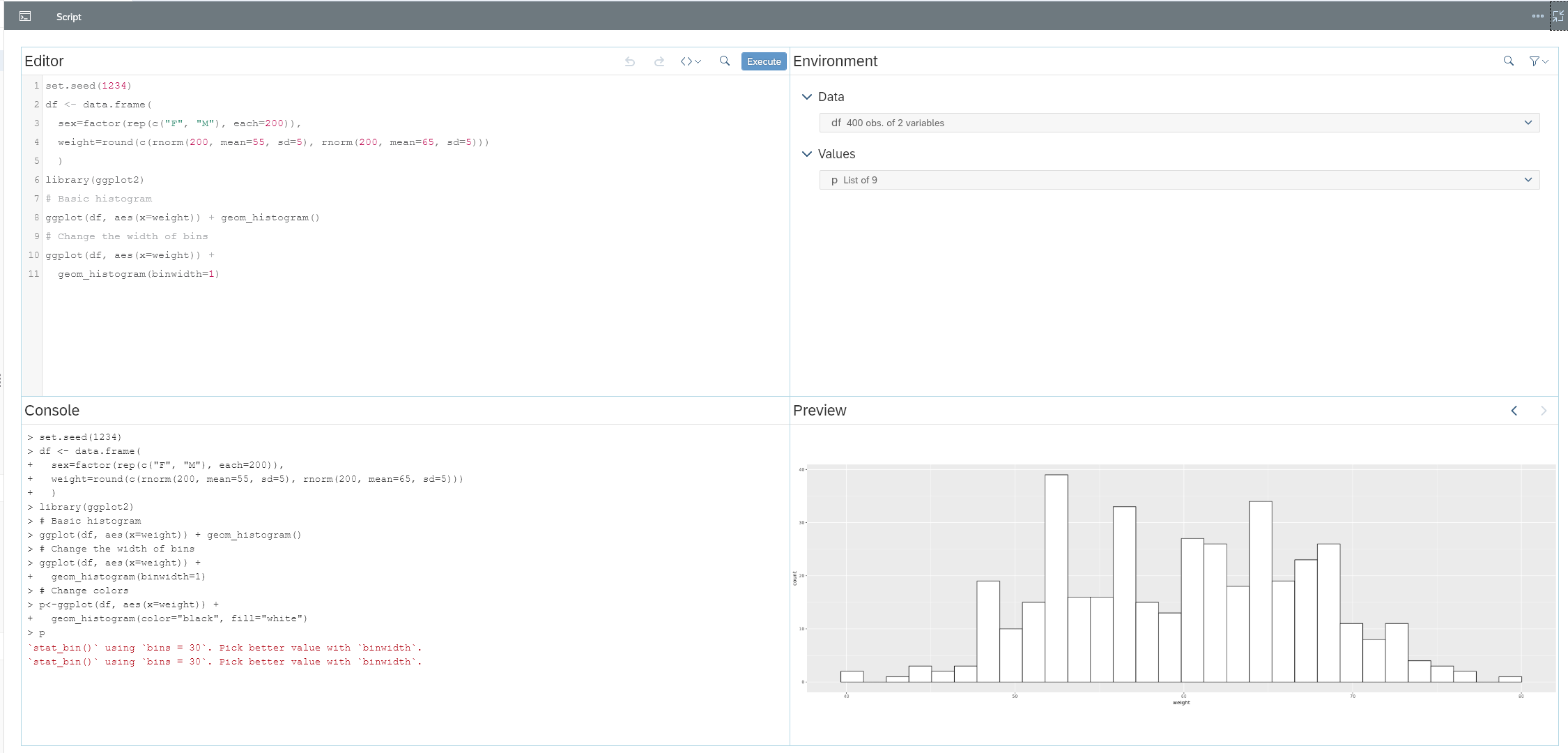
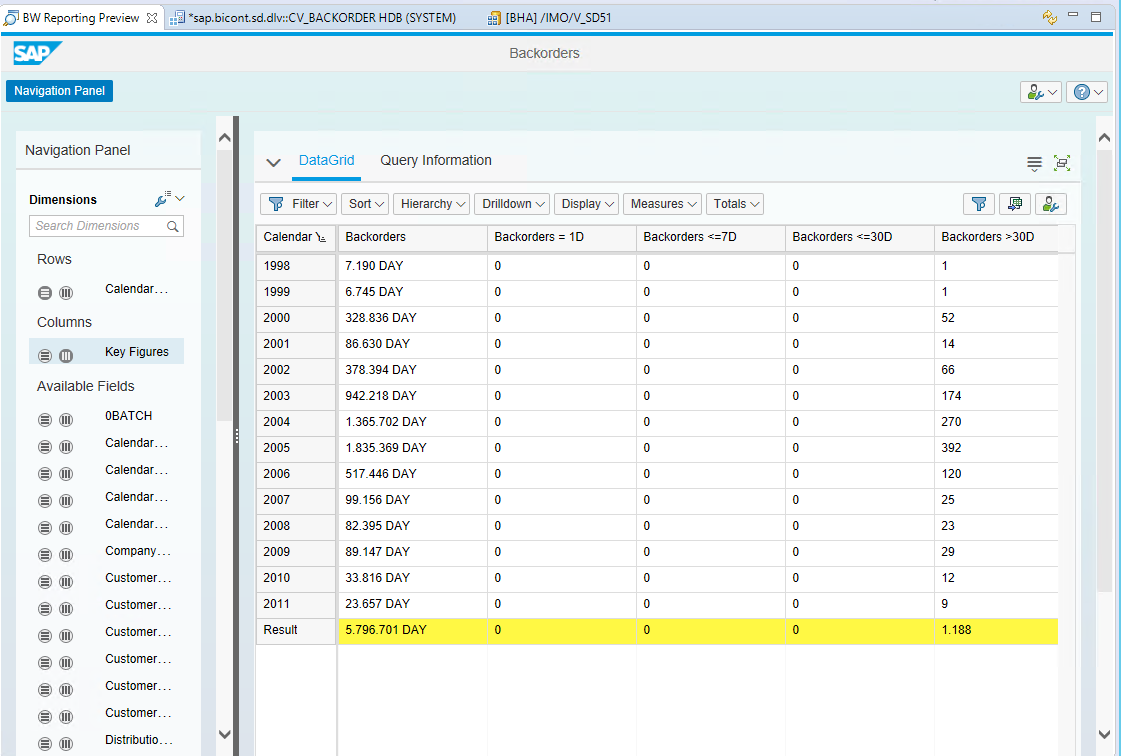
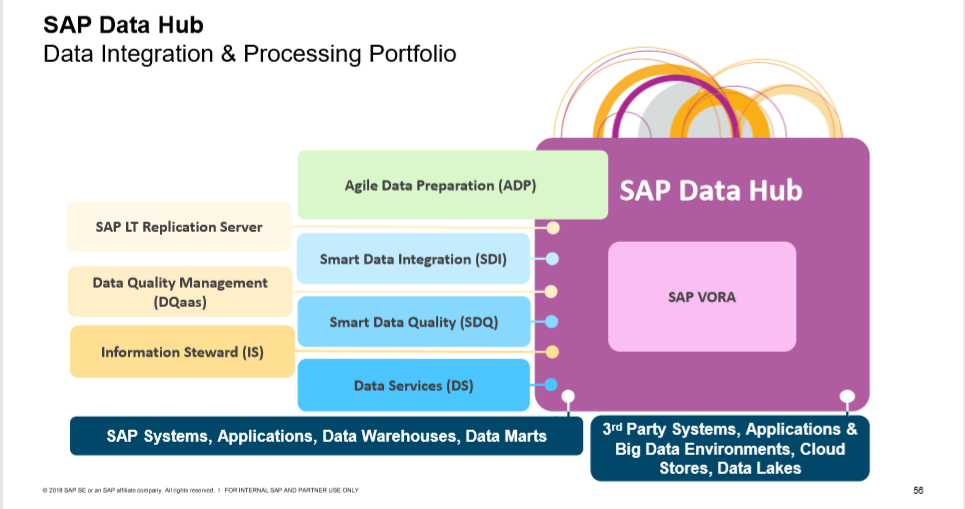
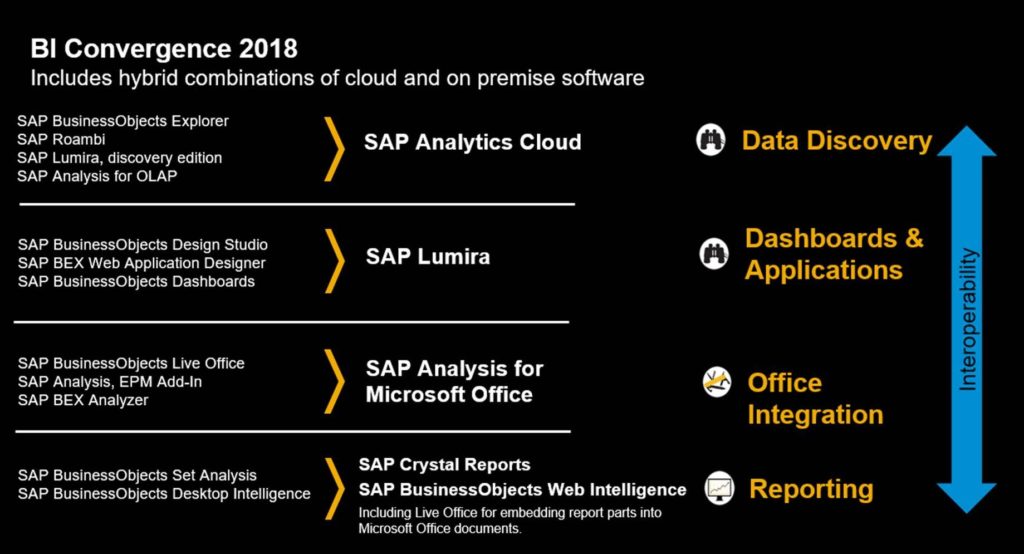
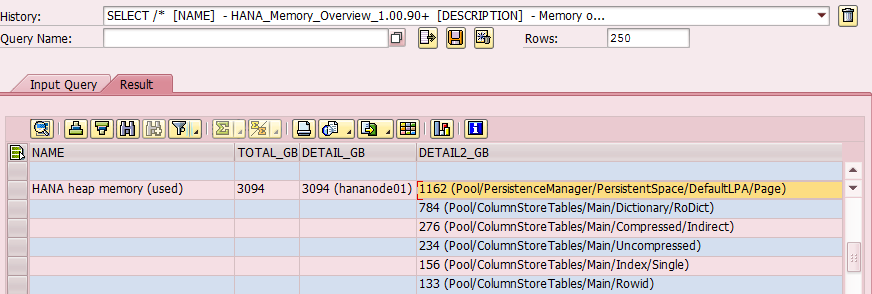
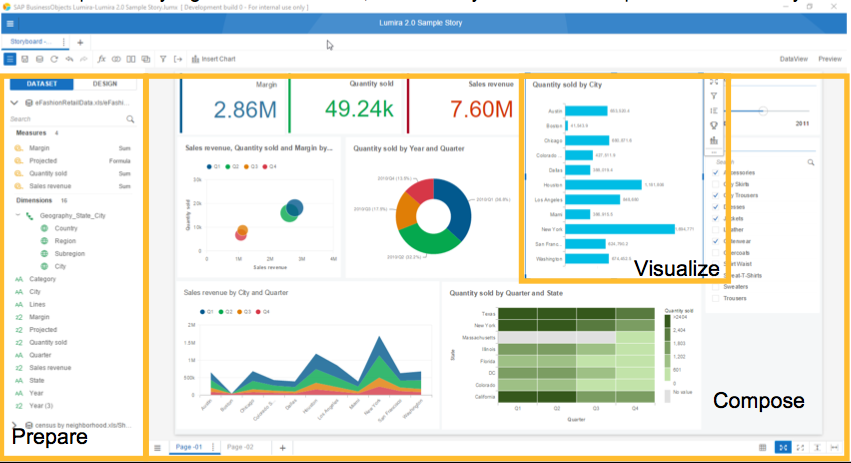
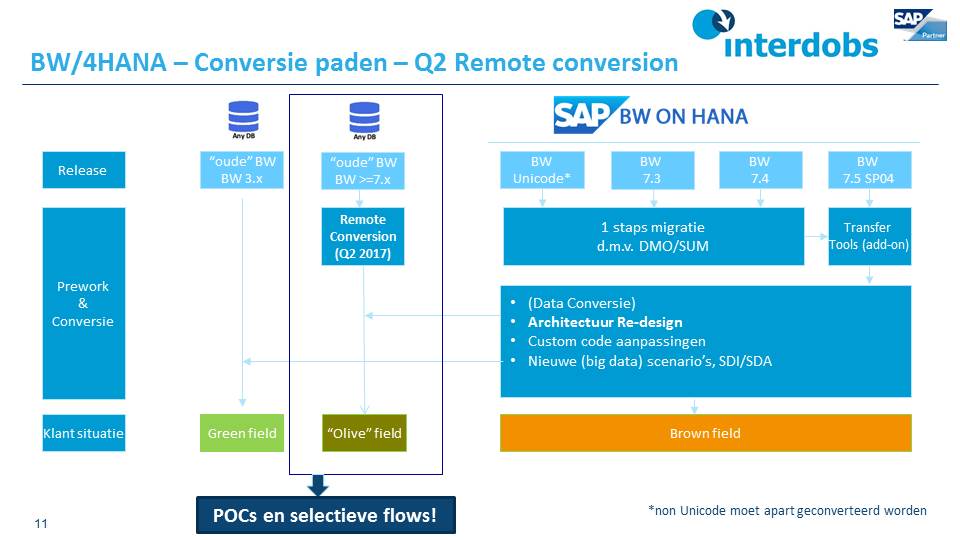
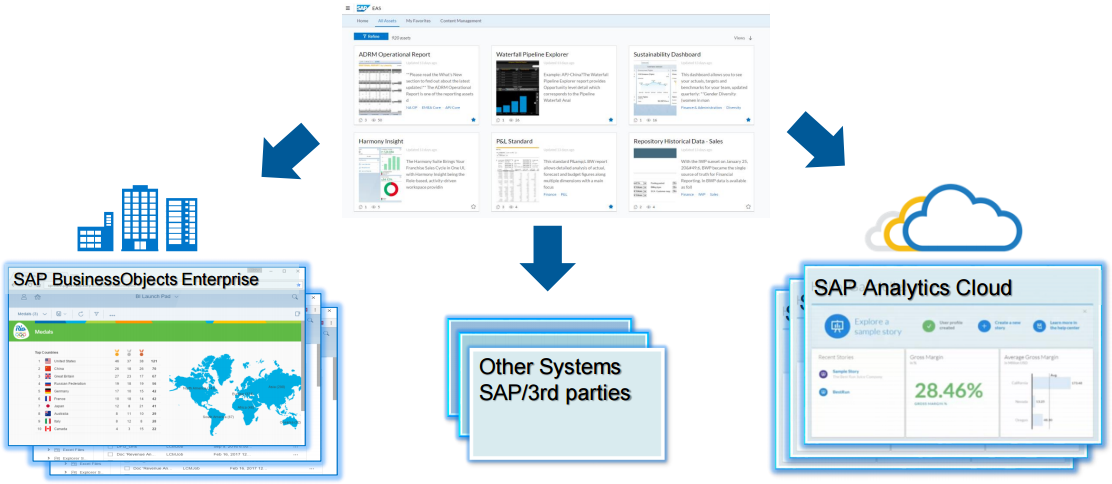
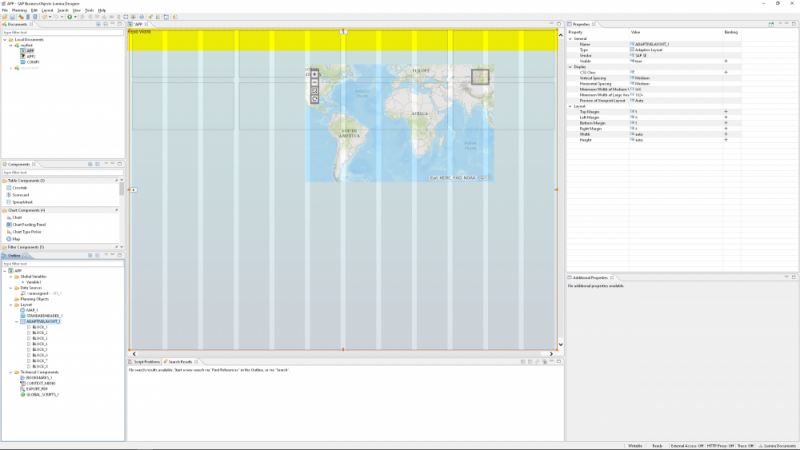
Interdobs Celebrates Award-Winning Innovation with SAP Datasphere and SAP Analytics Cloud
10 April 2024
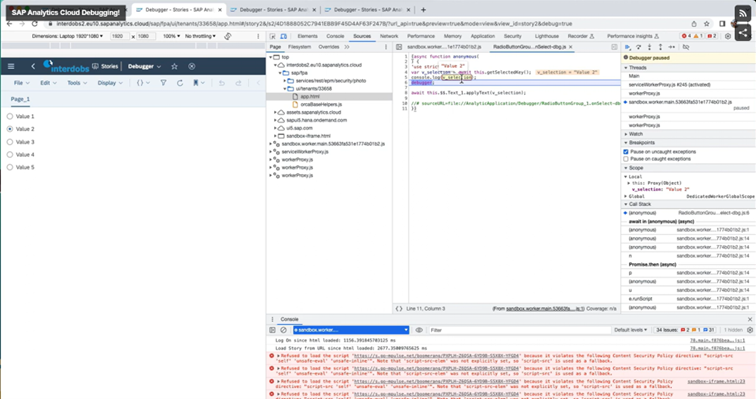
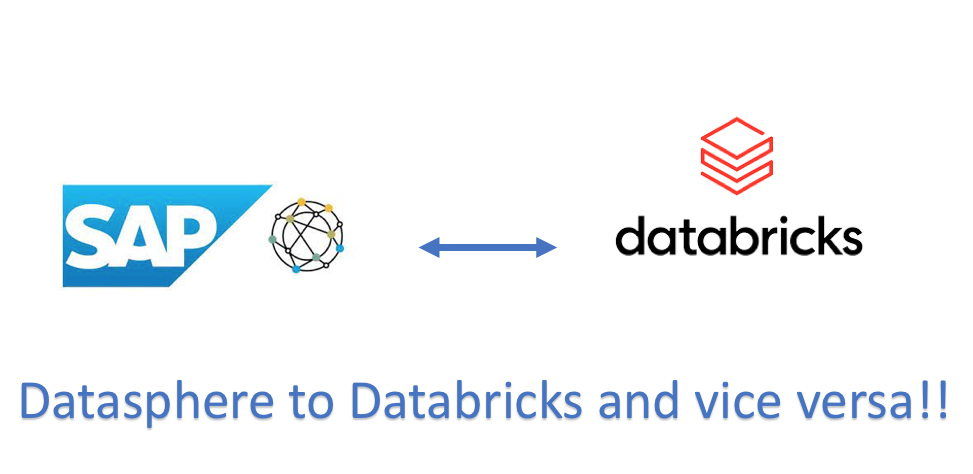
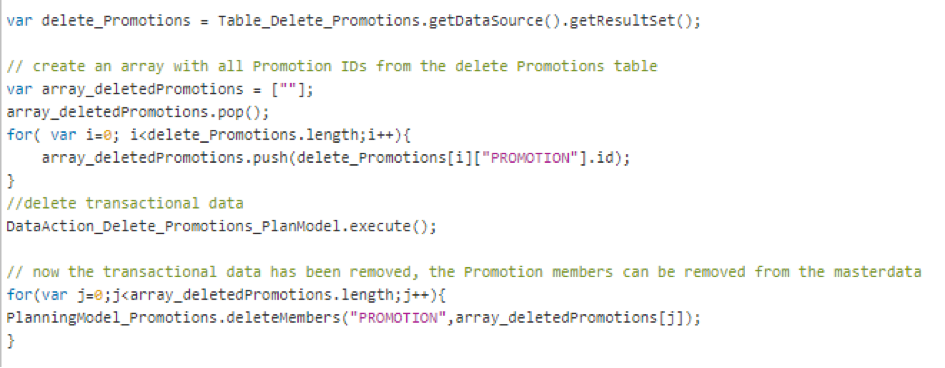
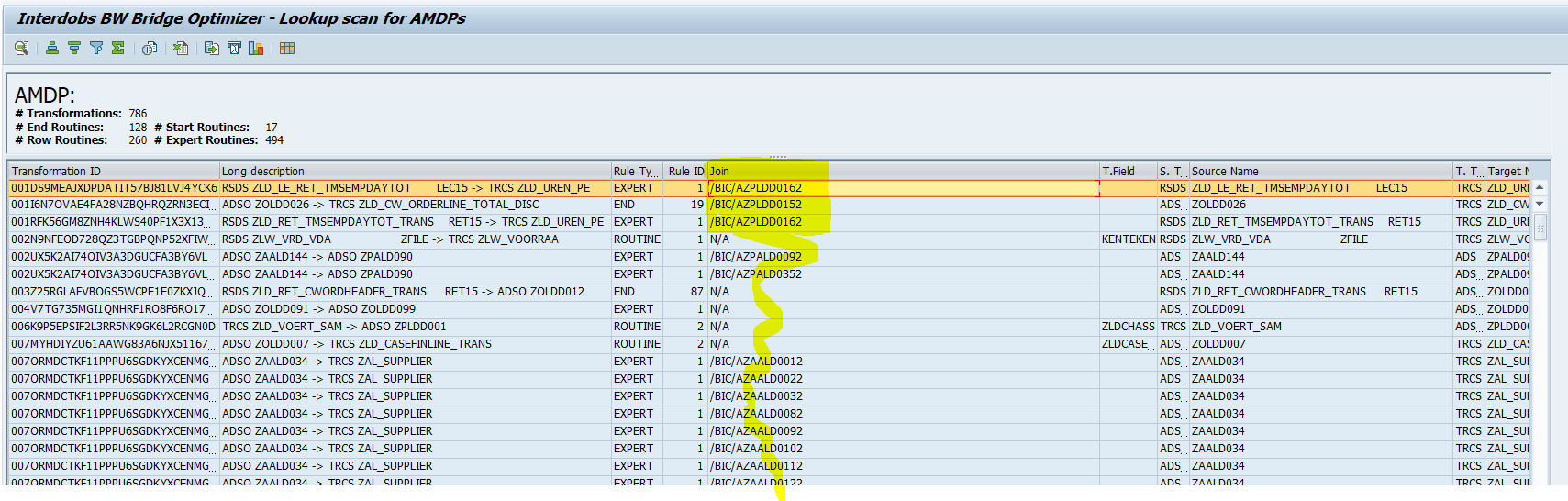
Our 4rd partner award and it never gets bored! Interdobs is thrilled to announce its recent accolade as the SAP Business Technology Platform Partner of the Year, a testament...
Read More